import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import RobustScaler, OneHotEncoder, LabelEncoder
from sklearn.cluster import KMeans,DBSCAN
from sklearn.impute import SimpleImputer
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import silhouette_score
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import hdbscan
from sklearn.ensemble import IsolationForest
columnas = ["BRAND", "LANGUAGE", "GENDER", "AGE", "PROVINCE", "CAR_MODEL",
"FUEL", "VEHICLE_AGE", "VEHICLE_AGE_RANGE",
"VISIT_WORKSHOP_DATE", "CURRENT_MILEAGE"]
df = pd.read_csv("CLIENT_CLUSTERING_2.csv", sep=";", header=None, names=columnas)
df = df[df["VEHICLE_AGE"] >= 0]
df = df[df["GENDER"] > 0]
df = df[(df["AGE"] > 18) & (df["AGE"] < 80)]
df = df[(df["PROVINCE"] >= 1) & (df["PROVINCE"] <= 52)]
def agrupar_fuel(f):
if pd.isna(f):
return "OTRO"
f = f.upper()
if f == "ESS":
return "GASOLINA"
elif f == "DIESEL":
return "DIESEL"
elif f == "ELEC":
return "ELECTRICO"
else:
return "OTRO"
def extraer_modelo_raiz(texto):
if pd.isna(texto):
return "DESCONOCIDO"
excluidos = {"NEW", "II", "III", "IV", "V", "BREAK", "VP", "VU", "VAN", "MCV", "E-TECH"}
palabras = texto.upper().split()
for palabra in palabras:
if palabra not in excluidos:
return palabra
return texto
df["FUEL"] = df["FUEL"].apply(agrupar_fuel)
codigos_provincias = {
1: "Álava",
2: "Albacete",
3: "Alicante",
etc...
}
df["PROVINCE"] = df["PROVINCE"].map(codigos_provincias)
codigo_a_comunidad = {
# Andalucía
4: "Andalucía", # Almería
11: "Andalucía", # Cádiz
14: "Andalucía", # Córdoba
18: "Andalucía", # Granada
21: "Andalucía", # Huelva
23: "Andalucía", # Jaén
29: "Andalucía", # Málaga
41: "Andalucía", # Sevilla
# Aragón
22: "Aragón", # Huesca
44: "Aragón", # Teruel
50: "Aragón", # Zaragoza
etc...
}
df['COMUNIDAD_AUTONOMA'] = df['PROVINCE'].apply(lambda x: codigo_a_comunidad.get(x, "Desconocido"))
df = df.drop('PROVINCE', axis=1)
df["CAR_MODEL"] = df["CAR_MODEL"].apply(extraer_modelo_raiz)
modelos_unicos = df["CAR_MODEL"].unique()
modelos_anonimos = {modelo: f"MODELO_{chr(65+i)}" for i, modelo in enumerate(modelos_unicos)}
df["CAR_MODEL"] = df["CAR_MODEL"].map(modelos_anonimos)
mapeo_rangos = {
"0 a 2": 0,
"0 a 4": 1,
"3 a 4": 2,
"5 a 10": 3
}
df["VEHICLE_AGE_RANGE"] = df["VEHICLE_AGE_RANGE"].map(mapeo_rangos)
df["VISIT_WORKSHOP_DATE"] = pd.to_datetime(df["VISIT_WORKSHOP_DATE"])
hoy = pd.Timestamp.today()
df["LAST_VISIT_DAYS"] = (hoy - df["VISIT_WORKSHOP_DATE"]).dt.days
df["LAST_VISIT_DAYS"] = df["LAST_VISIT_DAYS"].fillna(999)
df.drop("VISIT_WORKSHOP_DATE",axis=1,inplace=True)
df["BRAND"] = df["BRAND"].map({1: "MARCA_A", 2: "MARCA_B"})
df["GENDER"] = df["GENDER"].map({1: "HOMBRE", 2: "MUJER"})
df.to_csv("CLIENT_CLUSTERING_LIMPIO.csv", index=False)
num_cols = ["VEHICLE_AGE", "CURRENT_MILEAGE"]
cat_cols = ["BRAND", "LANGUAGE", "GENDER","CAR_MODEL","FUEL","COMUNIDAD_AUTONOMA"]
pass_cols = ["AGE", "VEHICLE_AGE_RANGE","LAST_VISIT_DAYS"]
num_pipeline = Pipeline([
("imputer", SimpleImputer(strategy="mean")),
("scaler", RobustScaler())
])
cat_pipeline = Pipeline([
("encoder", OneHotEncoder(handle_unknown="ignore"))
])
preprocessor = ColumnTransformer([
("num", num_pipeline, num_cols),
("cat", cat_pipeline, cat_cols),
("pass", "passthrough", pass_cols)
])
X_preprocessed = preprocessor.fit_transform(df)
pipeline = Pipeline([
("preprocessing", preprocessor),
("clustering", DBSCAN(eps=8.956, min_samples=28))
])
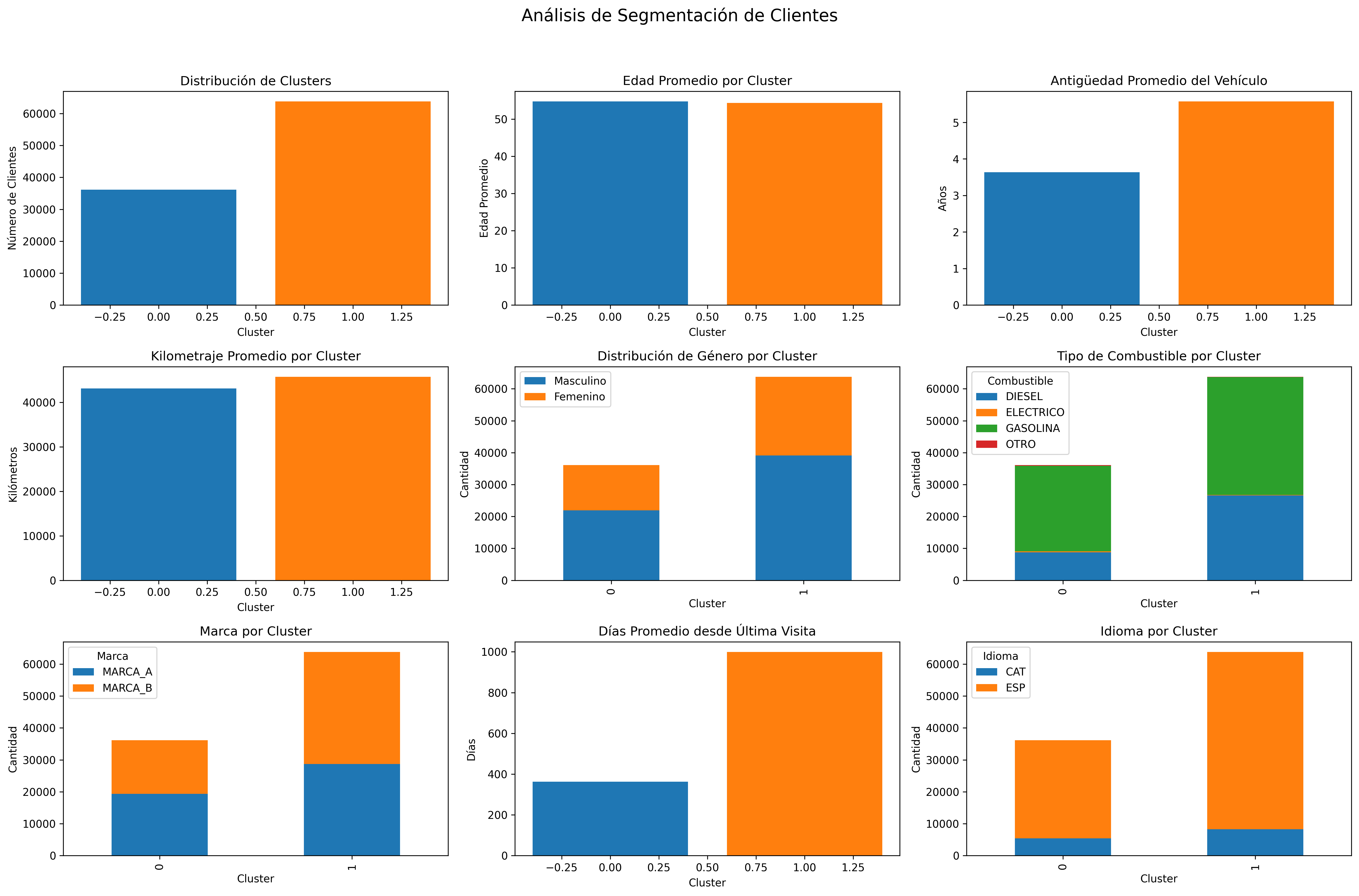
clusters = pipeline.fit_predict(df)
df["cluster"] = clusters