Predictor de Champiñones
Determina si un champiñón es comestible o venenoso basándose en sus características
Ejercicio de clasificación | Dataset Mushrooms de Kaggle
Código de Entrenamiento del Modelo
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import OneHotEncoder
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.metrics import f1_score, classification_report
# Cargar datos
df_origin = pd.read_csv("mushrooms.csv")
df = df_origin.copy()
# Preparar los datos
X, y = df.drop(['class'], axis=1), df['class']
# Aplicar mapeo para 'class'
mapeo = {'e': 0, 'p': 1}
y = y.map(mapeo)
# Split de datos
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
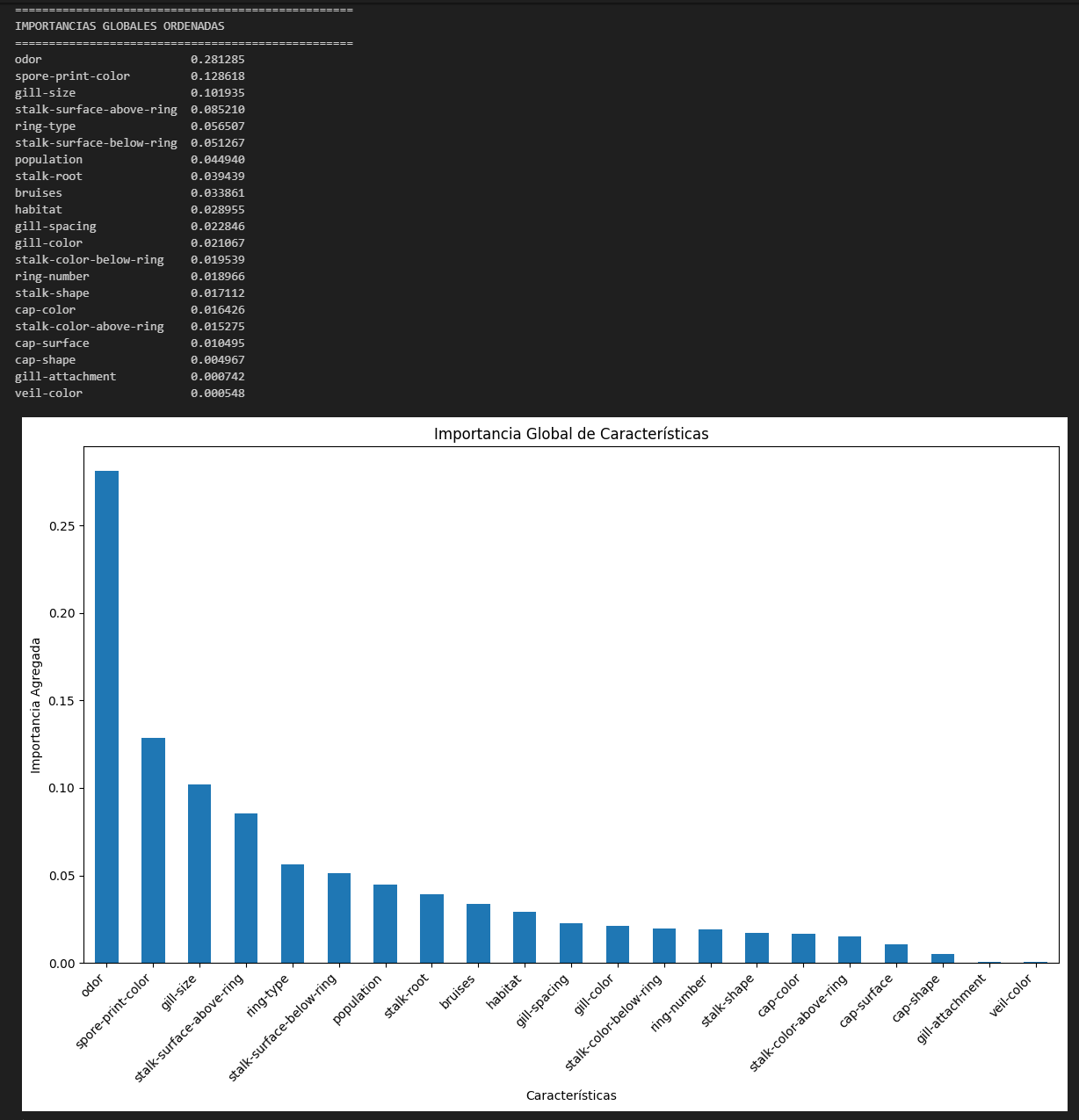
# PASO 1: CALCULAR IMPORTANCIAS GLOBALES
# Crear preprocessor temporal
temp_preprocessor = ColumnTransformer([
('categorical', OneHotEncoder(drop='first'), X_train.columns.tolist())
])
# Aplicar one-hot encoding
X_train_encoded = temp_preprocessor.fit_transform(X_train)
feature_names = temp_preprocessor.get_feature_names_out()
# Entrenar modelo temporal para obtener importancias
temp_model = RandomForestClassifier(n_estimators=100, random_state=42)
temp_model.fit(X_train_encoded, y_train)
# Agregar importancias por característica base
global_importances = {}
for feature_name, importance in zip(feature_names, temp_model.feature_importances_):
base_feature = feature_name.split('_')[0].replace('categorical__', '')
global_importances[base_feature] = global_importances.get(base_feature, 0) + importance
# Seleccionar las 10 características más importantes
global_importances_series = pd.Series(global_importances).sort_values(ascending=False)
top_10_features = global_importances_series.head(10).index.tolist()
# PASO 2: CREAR DATAFRAME FILTRADO
X_train_filtered = X_train[top_10_features].copy()
X_test_filtered = X_test[top_10_features].copy()
# PASO 3: APLICAR PIPELINE AL DATAFRAME FILTRADO
# Crear preprocessor para las características filtradas
preprocessor = ColumnTransformer([
('categorical', OneHotEncoder(drop='first'), X_train_filtered.columns.tolist())
])
# Pipeline completo
ml_pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', RandomForestClassifier(
n_estimators=100,
max_depth=10,
min_samples_leaf=5,
random_state=42
))
])
# Entrenar el pipeline
ml_pipeline.fit(X_train_filtered, y_train)
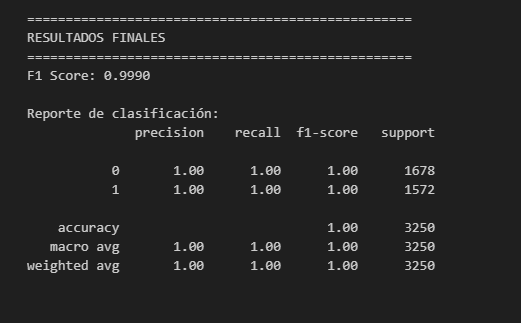
# Evaluar
y_pred = ml_pipeline.predict(X_test_filtered)
print(f"F1 Score: {f1_score(y_test, y_pred, average='binary'):.4f}")
# Guardar modelo
import joblib
model_info = {
'pipeline': ml_pipeline,
'selected_features': top_10_features,
'feature_importances': global_importances_series
}
joblib.dump(model_info, 'modelo-mushrooms.joblib')
Análisis de Datos del Modelo