Predictor de Sueldos
Completa el formulario para obtener una predicción de sueldo anual
Ejercicio de regresión | Dataset generado con ChatGPT
Código de Entrenamiento del Modelo (Pipeline)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.compose import ColumnTransformer, TransformedTargetRegressor
from sklearn.preprocessing import OneHotEncoder, PowerTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from scipy.stats import randint
# Cargar datos
df_origin = pd.read_csv("dataset_sueldos.csv")
df = df_origin.copy()
# Preparar los datos
X, y = df.drop(['Sueldo_Anual'], axis=1), df['Sueldo_Anual']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
# Definir las columnas por tipo
numeric_features = ['Edad', 'Experiencia_Anios', 'Horas_Semanales']
categorical_features = ['Nivel_Educativo', 'Industria','Ubicación','Género']
# Crear el preprocessor para las features
preprocessor = ColumnTransformer([
('numeric', 'passthrough', numeric_features),
('categorical', OneHotEncoder(drop='first'), categorical_features)
])
# Pipeline completo con preprocessor + modelo
ml_pipeline = Pipeline([
('preprocessor', preprocessor),
('model', RandomForestRegressor(random_state=42))
])
# Añadir Box-Cox al target con TransformedTargetRegressor
final_model = TransformedTargetRegressor(
regressor=ml_pipeline,
transformer=PowerTransformer(method='box-cox')
)
# Definir parámetros para RandomizedSearchCV
param_distributions = {
'regressor__model__n_estimators': randint(20, 200),
'regressor__model__max_depth': [None] + list(range(5, 30)),
'regressor__model__min_samples_split': randint(2, 20),
'regressor__model__min_samples_leaf': randint(1, 10),
'regressor__model__max_features': ['sqrt', 'log2', None],
'regressor__model__bootstrap': [True, False]
}
# Búsqueda de hiperparámetros
random_search = RandomizedSearchCV(
estimator=final_model,
param_distributions=param_distributions,
n_iter=50,
cv=5,
scoring='neg_mean_squared_error',
n_jobs=-1,
verbose=1,
random_state=42
)
# Entrenar modelo
print("Iniciando optimización de hiperparámetros...")
random_search.fit(X_train, y_train)
best_model = random_search.best_estimator_
# Guardar modelo
import cloudpickle
with open('modelo_sueldos.pkl', 'wb') as f:
cloudpickle.dump(best_model, f)
# Evaluar modelo
from sklearn.metrics import r2_score
y_pred = best_model.predict(X_test)
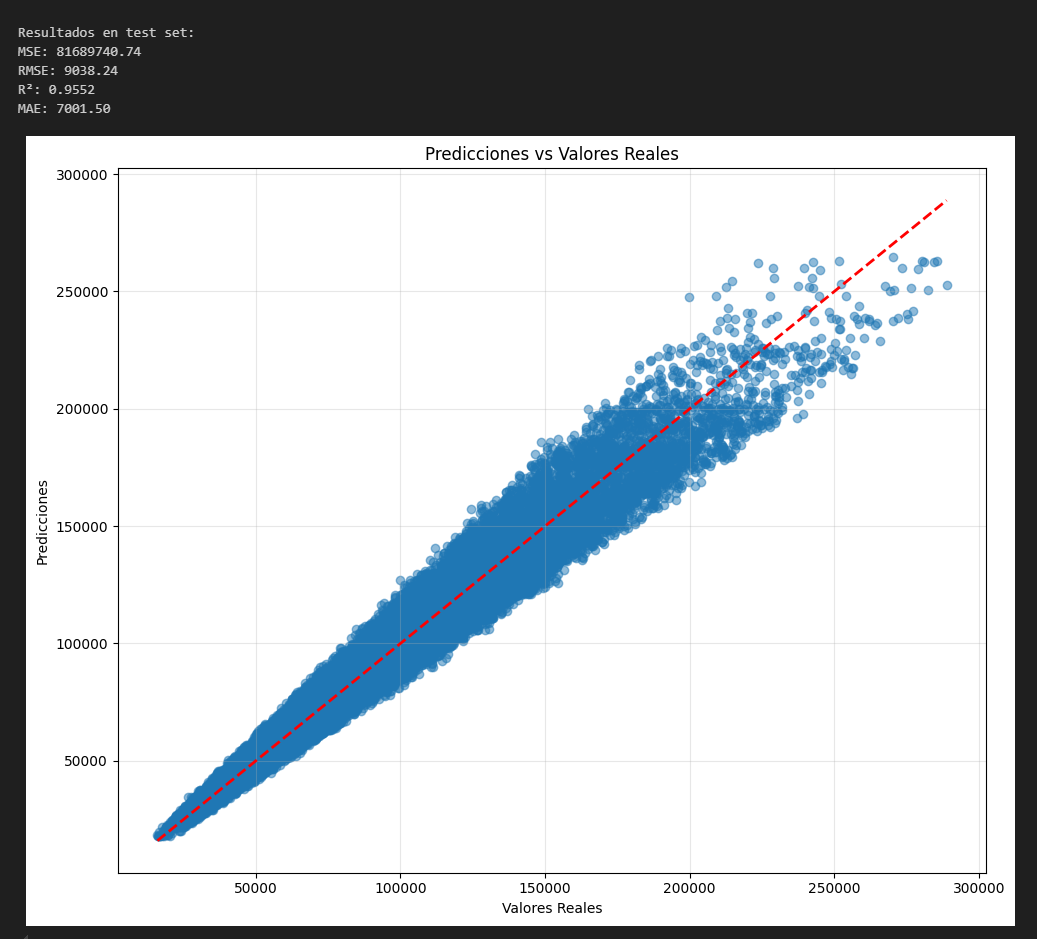
print(f"R² en test: {r2_score(y_test, y_pred):.4f}")Análisis de Datos del Modelo